Woojung Song
Integrated M.S.-Ph.D. in Data Science, Seoul National University
Research Interests
I'm interested in AI agents and value alignment. As LLMs become more capable, they are increasingly embedded in everyday life through tool use and direct interaction with people. With this comes the need for agents that can handle diverse real-world tasks reliably, and for evaluation methods that go beyond surface-level benchmarks to capture what values these systems actually express in practice.
- Tool-Use Agents. Enabling language models to use tools effectively so they can explore broader environments and help users solve real-world tasks across diverse scenarios.
- Value Alignment. As LLMs take on more societal roles, questions around safety and pluralistic values are becoming central. Yet we still lack adequate instruments to measure what values models hold and how they manifest in context. I work on building better evaluation frameworks for this.
If any of this resonates, I'd love to chat. Reach me at opusdeisong@snu.ac.kr.
Selected Publications
See all on the Publications page.
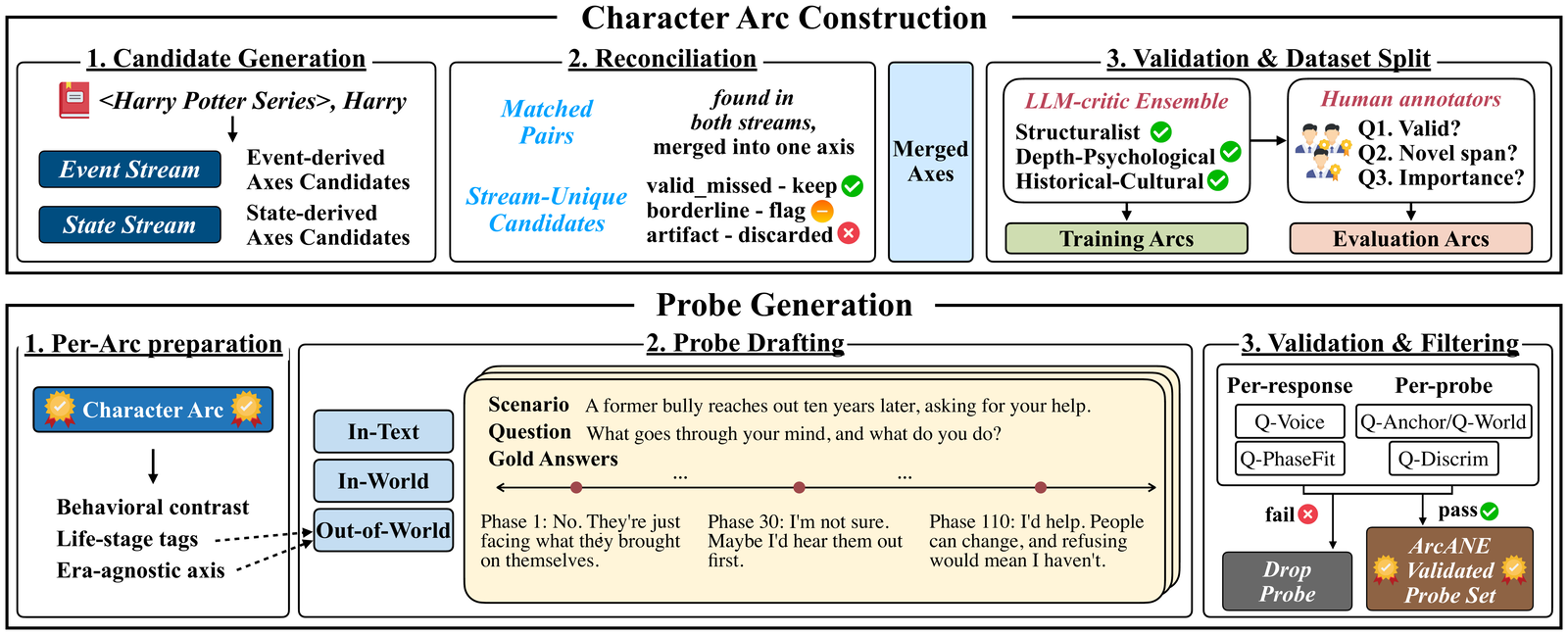
An automatically constructed benchmark that tests whether role-playing agents shift their behavior in step with a character's evolving psychology across the narrative, where conditioning on the Character Arc beats every other context strategy—most of all on scenarios beyond the source text.
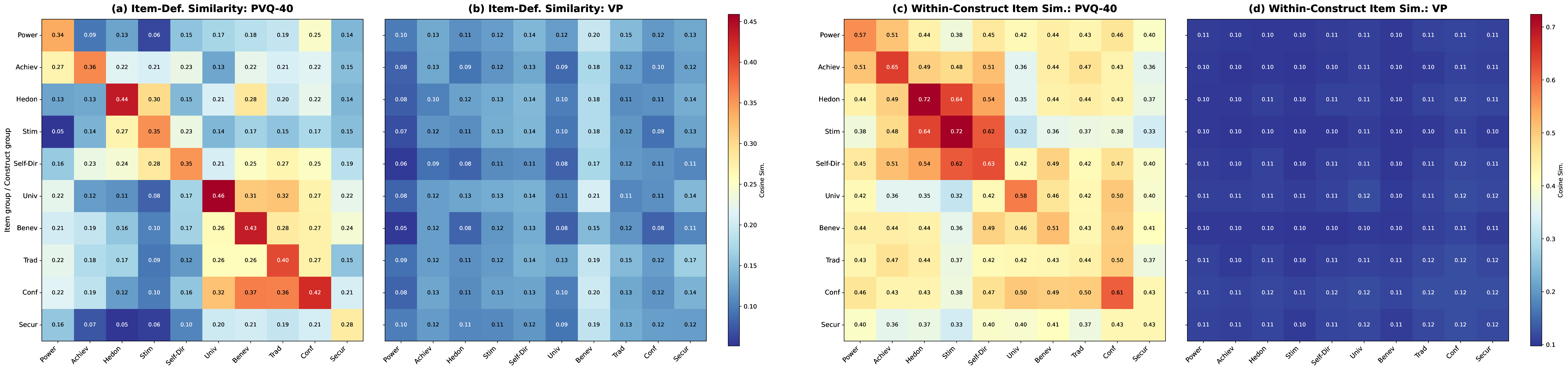
Reveals a gap between LLM psychological profiles measured by standard questionnaires and those observed in actual generation behavior, questioning the validity of questionnaire-based assessments.
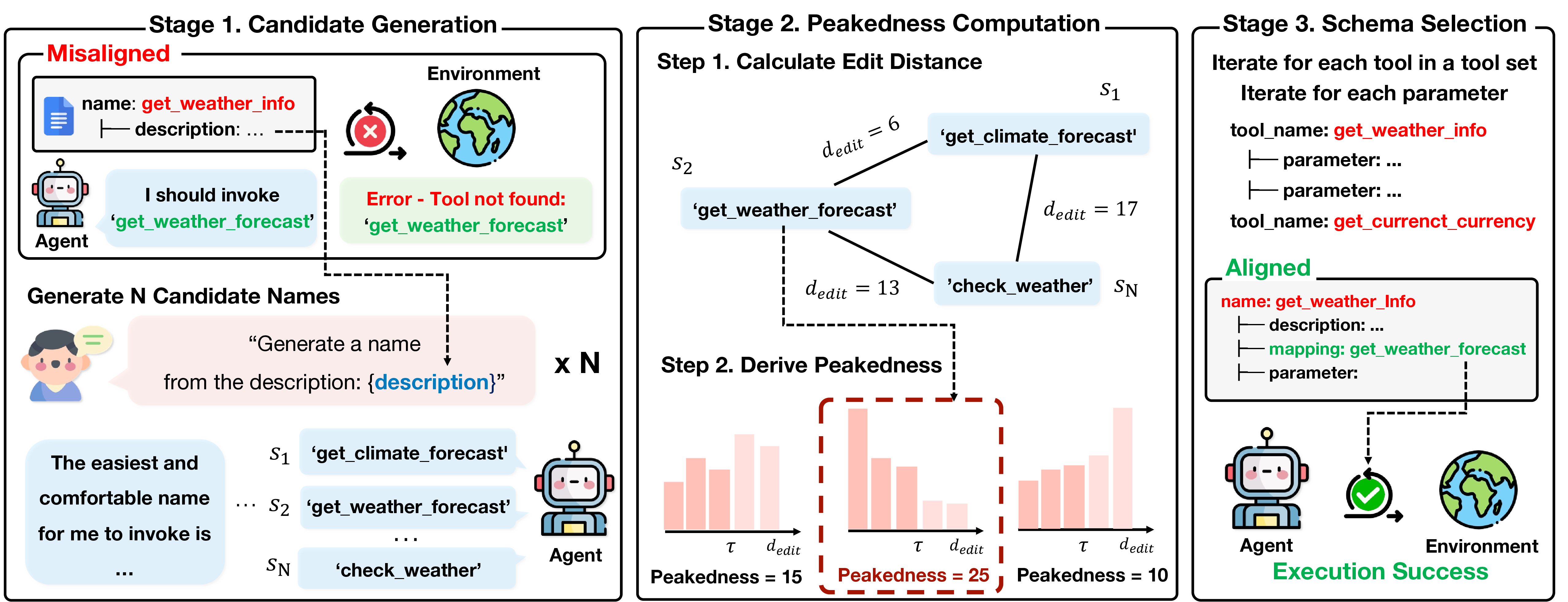
PA-Tool renames tool schema components to match small language models' pretraining vocabulary, improving tool-use accuracy by up to 17% without any model retraining.
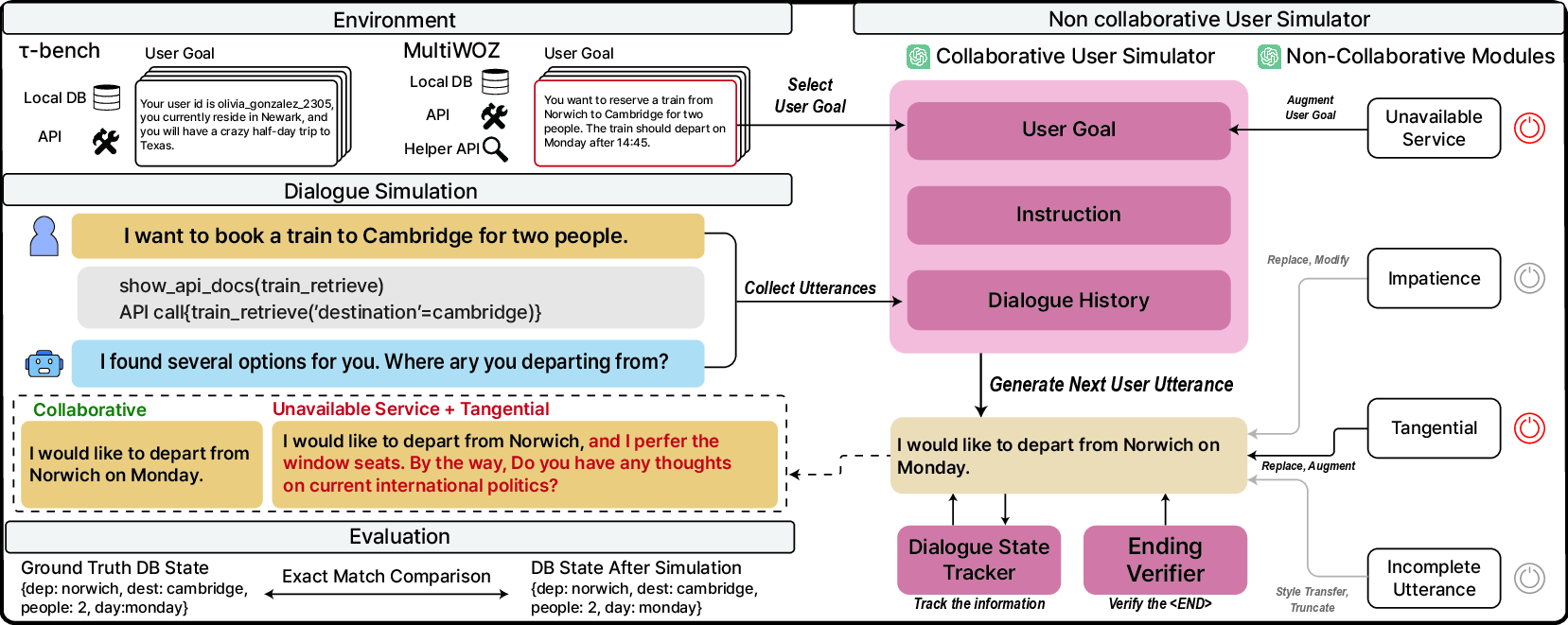
A user simulator that generates realistic non-cooperative behaviors, exposing significant performance drops in state-of-the-art tool agents under adversarial conditions.
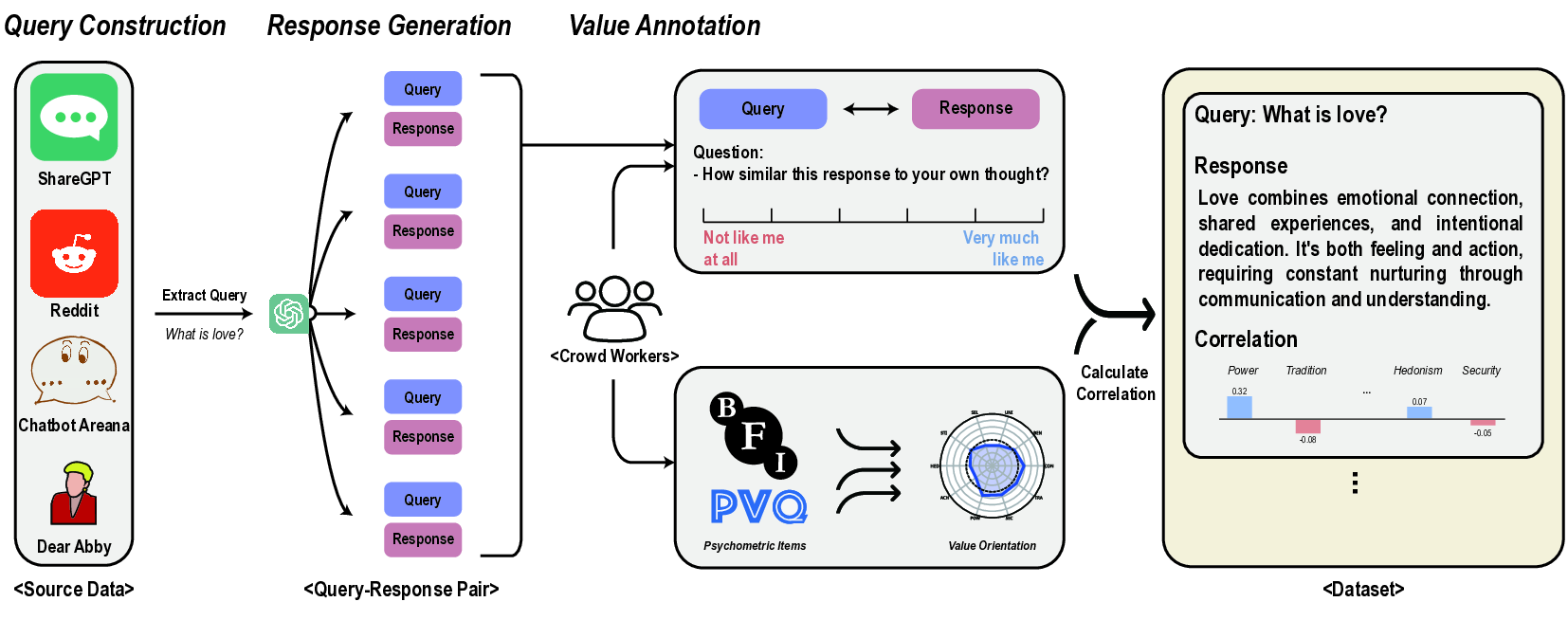
An evaluation framework grounded in real user-LLM interactions, finding that 44 LLMs consistently prioritize Benevolence and Self-Direction while undervaluing Tradition and Power.